RAG 工作机制详解——一个高质量知识库背后的技术全流程
RAG 工作机制详解——一个高质量知识库背后的技术全流程
原视频来源:B站 · 马克的技术工作坊
本文为视频内容的结构化整理与延展讲解,方便收藏查阅。
如果你想做一个靠谱的知识客服,或者搭建一个能回答问题的知识库,那就一定绕不开一个技术——RAG。
它的全称是 Retrieval Augmented Generation,翻译过来就是”检索增强生成”。听起来挺高大上,但说白了就两件事:
- 先从资料库里检索相关的内容
- 再基于这些内容来生成答案
先检索、再生成,所以叫做”检索增强生成”。它是目前最常用的 AI 问答方案之一,企业内的知识助手、智能客服用的都是这项技术。
一、为什么需要 RAG
假设你想做一个能回答公司产品问题的智能客服。
最直接的想法是:客服内部接一个 LLM(比如 GPT-4o、DeepSeek),每次把产品手册一起发给模型就行。这确实是一种方案,但如果手册有上百页甚至上千页,就会带来三个严重问题:
| 问题 | 说明 |
|---|---|
| 上下文窗口不够 | 每个模型只能容纳一定量的信息(上下文窗口),手册过长会导致”读了后面忘前面” |
| 推理成本高 | 输入越多,Token 消耗越大,每次回答都带一本手册,成本不可承受 |
| 推理速度慢 | 输入越多,模型需要消化的内容越多,输出会越慢 |
直接把整个文档丢给模型显然不行。那能不能只把文档中相关的内容发给模型?可以,这就是 RAG 要解决的问题。
RAG 的思路非常朴素:
- 先把文档切分成多个片段
- 当用户提问时,在所有片段里寻找与问题相关的内容
- 只把相关的几个片段和用户问题一起发给大模型
比如一份上百页的产品手册,可能只有 3 个片段真正与用户问题相关,那就只把这 3 个片段送给大模型。既节省了上下文,也提升了准确率和响应速度。
二、RAG 整体流程
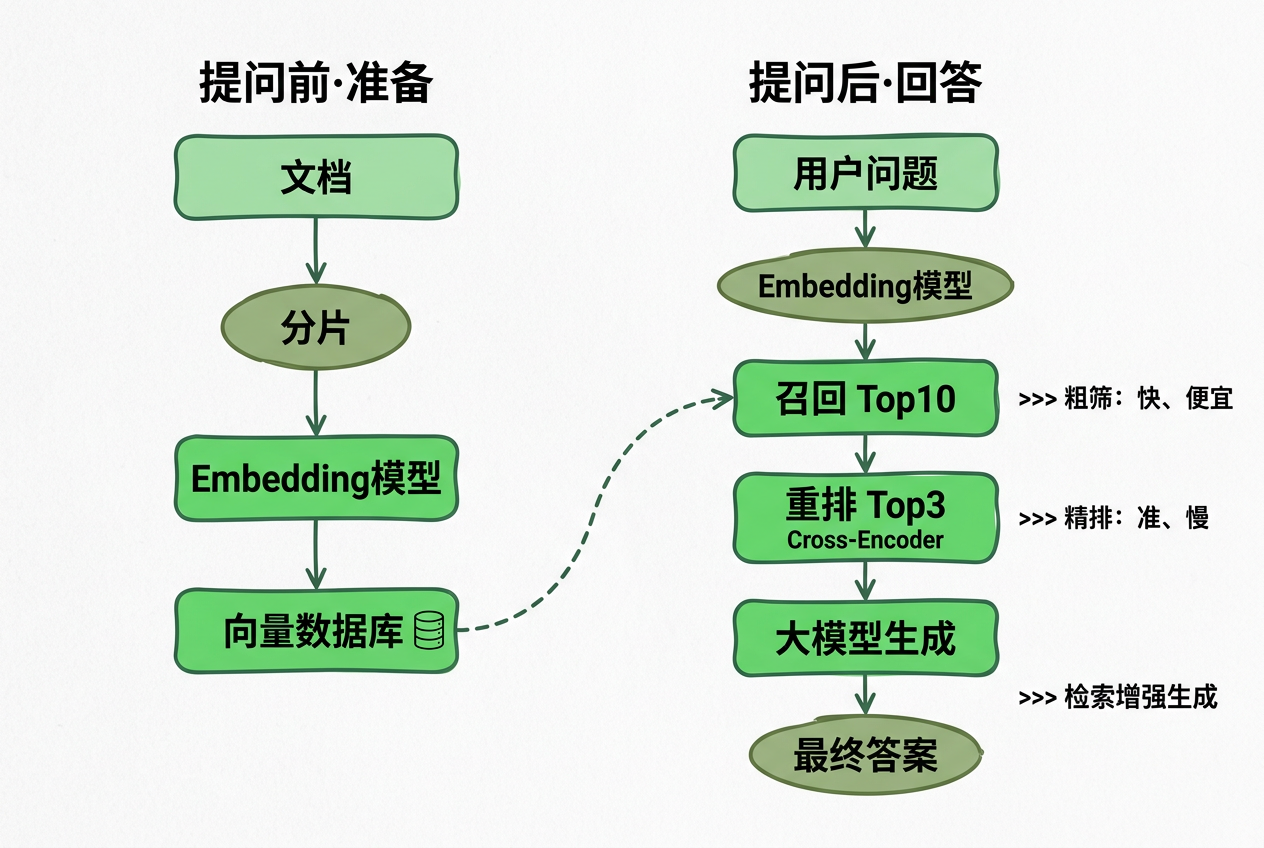
RAG 的完整流程包含两个部分、五个环节:
提问前:数据准备(离线)
- 分片(Chunking)
- 索引(Indexing)
提问后:问答回答(在线)
- 召回(Retrieval)
- 重排(Rerank)
- 生成(Generation)
下面我们依次拆解每个环节。

三、分片(Chunking)
分片顾名思义,就是把一篇文档切成多个小片段。常见的切分方式:
- 按字数切(如每 1000 字一个片段)
- 按段落切
- 按章节切
- 按页码切
- 其他策略(语义切分、滑动窗口等)
不管用哪种方式,目标都是:把一篇长文档切成多个大小合适的片段,切好后这个环节就结束了。
为什么分片很重要? 片段的粒度直接决定了后续召回的准确率。太大 → 混入噪声;太小 → 上下文不完整。
四、索引(Indexing)
索引就是通过 Embedding,把每一个片段文本转换为向量,然后把”片段文本 + 对应向量”一起存入向量数据库的过程。
这句话里有三个关键概念:向量、Embedding、向量数据库。我们先逐个讲清楚,再回头看索引。
4.1 什么是向量
向量是数学里的概念——一个”有大小、有方向”的量,通常可以用一个数组来表示。
- 一维向量:
[1]、[3] - 二维向量:
[2, 2]、[1, 2] - 三维向量:
[1, 2, 3] - …
数组中数字的个数就是向量的维度。低维向量可以在坐标系里画出来,但我们在 RAG 里用的向量通常是几百甚至几千维——肉眼看不见,但不影响它存在。
维度越大,每个向量所能承载的信息就越丰富,可靠性也越强。
4.2 什么是 Embedding
Embedding 就是把文本转换为向量的过程。 关键特性是:
含义相近的文本,经过 Embedding 之后,对应的向量也会相近。
举个二维向量的例子:
| 文本 | 向量 |
|---|---|
| 马克喜欢吃水果 | [1, 2] |
| 马克爱吃水果 | [1, 1] |
| 天气真好 | [3, -1] |
可以看到前两句的向量非常接近,而”天气真好”则离得很远——这正是 Embedding 希望达到的效果:把语义的相似度,映射成空间上的距离。
Embedding 的工作由专门的 Embedding 模型完成,它和我们常用的 GPT-4o、DeepSeek 这类生成模型不是一回事。
🔗 想挑选 Embedding 模型可以看 MTEB 排行榜,各类模型的评测结果一目了然。
4.3 什么是向量数据库
向量数据库就是专门用来存储和查询向量的数据库,它做了很多针对向量的优化,并内置了向量相似度计算等函数。
往里存的时候,我们不仅要存向量,还要存原始文本。原因很简单:查询时通过相似度找到的是向量,但最终要送给大模型的仍然是原始文本——向量只是一个中间表示。
所以一张典型的向量表至少有两列:
| 原始文本 | 向量 |
|---|---|
| 马克喜欢吃水果 | [0.12, 0.88, ..., 0.04] |
| … | … |
4.4 回头看索引
理解了上面三个概念,再看索引就顺理成章了:
- 拿到第一个片段 → 送入 Embedding 模型 → 得到向量 → 把”片段文本 + 向量”一起写入向量数据库
- 处理第二个片段、第三个片段……
- 所有片段处理完,索引流程结束
到这里,”提问前的数据准备”就完成了,相当于知识库已经构建好,坐等用户提问。
五、召回(Retrieval)
召回是用户提问后的第一步:从所有片段中,搜索出与用户问题相关的若干个。流程如下:
- 用户问题 → 发给 Embedding 模型 → 转成向量
- 把这个向量发给 向量数据库
- 向量数据库根据向量相似度,返回与用户问题最相似的 Top K(例如 10)个片段
K 的具体数字(10、15、20 等)不是关键,只要数量不太大都可以。
向量相似度怎么算
向量数据库判断”哪些片段最相关”,靠的是向量相似度。主流的计算方法有三种:
| 方法 | 核心思想 |
|---|---|
| 余弦相似度(Cosine Similarity) | 计算两个向量夹角的 cos 值,夹角越小(cos 值越大),相似度越高 |
| 欧氏距离(Euclidean Distance) | 计算两个向量端点之间的几何距离,距离越小相似度越高 |
| 点积(Dot Product) | 兼顾方向与长度:方向一致且模长越大,点积越大;方向相反为负;垂直为 0 |
向量数据库会对每个片段算一次相似度,排序后取前 K 个最相似的作为召回结果。
六、重排(Rerank)
重排做的事情和召回看起来一样——挑出与用户问题最相关的片段,但它只在召回返回的 K 个里面再挑几个(比如 3 个)。
你可能会问:为什么不在召回时直接挑 3 个,省事多了?
因为召回和重排用的是不同的相似度计算逻辑,各有取舍。
召回 vs 重排
| 维度 | 召回 | 重排 |
|---|---|---|
| 使用技术 | 向量相似度(Cosine / Euclidean / Dot) | Cross-Encoder 模型 |
| 成本 | 低 | 较高 |
| 速度 | 快 | 较慢 |
| 准确率 | 较低 | 较高 |
| 角色 | 粗筛(从上千里选 10 个) | 精排(从 10 个里选 3 个) |
用招聘来类比
你可以把召回和重排想象成公司招聘的两个环节:
- 召回 ≈ 简历筛选:候选人太多(上千份简历),只能用粗略标准(关键词、学历),快速筛出 10 个看起来不错的,准确率一般但速度必须快。
- 重排 ≈ 面试:对这 10 个人深度考察,尽可能选出真正最优秀的 3 个。
先用便宜的方法缩小范围,再用昂贵的方法精挑细选——这就是”召回 + 重排”两段式架构的价值所在。
七、生成(Generation)
生成就是最后的答题环节。此时我们已经有:
- 用户问题
- 与问题最相关的 3 个片段(重排后的结果)
把它们一起打包发给大模型(如 GPT-4o、DeepSeek 等),让模型基于提供的片段生成答案。整个 RAG 流程到此结束。
八、端到端回顾
最后把整个流程串起来回顾一遍。
提问前(离线):构建知识库
1 | 原始文档 |
提问后(在线):回答问题
1 | 用户问题 |
九、核心要点速查
- RAG = 先检索、再生成,解决 LLM 上下文有限、成本高、速度慢的问题。
- 五大环节:分片、索引(提问前)→ 召回、重排、生成(提问后)。
- Embedding:把文本映射到向量空间,让”语义相近”变成”距离相近”。
- 向量数据库:不仅存向量,也存原始文本。
- 召回 vs 重排:粗筛(快、便宜、向量相似度) → 精排(慢、贵、Cross-Encoder)。
- 向量相似度:余弦相似度、欧氏距离、点积三选一。
结语
RAG 并不神秘,它本质上就是给大模型配一个”会查资料的助手”——查得好不好,取决于每个环节的工程细节:分片粒度、Embedding 质量、向量维度、相似度公式、重排模型、Prompt 拼接方式……
把这五步每一步都做好,才能得到一个真正高质量的知识库或智能客服。
💡 延伸阅读:MTEB Embedding 模型排行榜 · 原视频链接