Token 到底是什么?揭秘大模型背后的"文字压缩术"
Token 到底是什么?揭秘大模型背后的”文字压缩术”
本文整理自 B 站 UP 主 马克的技术工作坊 的视频 《Token 到底是什么?—— 揭秘大模型背后的”文字压缩术”》(20.3 万播放),并补充了额外的知识点和实践建议。
你可能每天都在用大模型,但如果我问你:40 万 Context Window,到底能装多少内容? 你能准确回答吗?
大多数人对 Token 的理解停留在”大概就是字”——但这个模糊的认知,会让你在写 Prompt、算成本、管 Context 的时候踩一堆坑。
一、大模型的基本工作原理
在理解 Token 之前,先快速回顾大模型是怎么工作的:
1 | 用户输入文本 → Tokenizer 编码为数字 → 模型处理 → 预测下一个 Token → Tokenizer 解码为文字 |
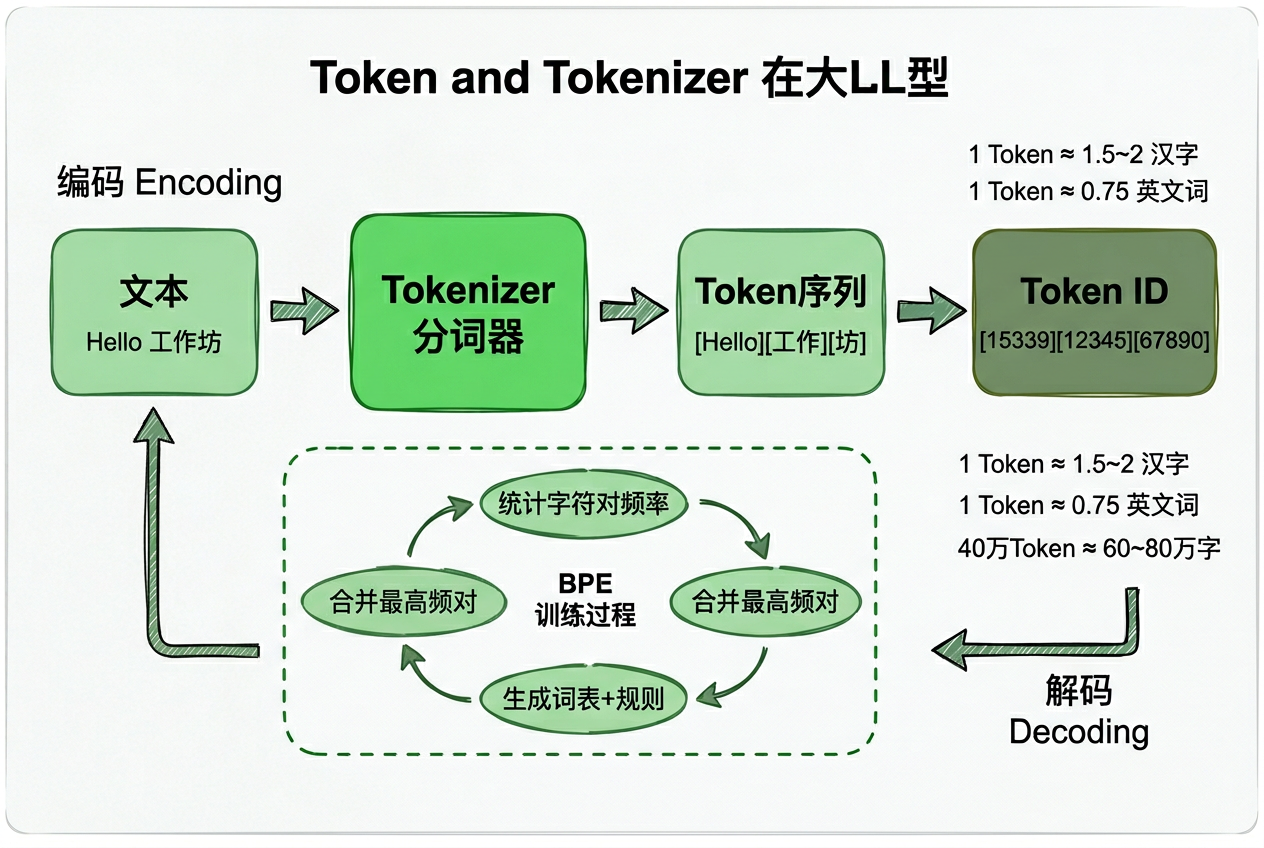
大模型只认识数字,不认识文字。所以需要一个”翻译官”在文字和数字之间来回转换——这就是 Tokenizer(分词器)。
而 Token,就是 Tokenizer 切分出来的最小文本片段。
二、Token 的本质
2.1 Token ≠ 字 ≠ 词
Token 是大模型处理文本的最小基本单位,它既不等于”字”,也不等于”词”,而是介于两者之间的 亚词(subword)单元。
2.2 分词示例
| 输入文本 | 分词结果 | Token 数 |
|---|---|---|
Hello |
[Hello] |
1 |
unbelievable |
[un] [believ] [able] |
3 |
中国 |
[中国] |
1(高频词) |
工作坊 |
[工作] [坊] |
2 |
人工智能 |
[人工] [智能] |
2 |
程序员 |
[程序] [员] |
2 |
☑ |
[â] [ś] [ij] |
3(特殊符号) |
规律总结:
- 高频词(如 “Hello”、”中国”)→ 通常 1 个 Token
- 长词/罕见词(如 “unbelievable”)→ 被拆成多个 Token
- 中文通常比英文”费”Token,因为汉字组合更多样
三、Tokenizer 的训练过程(BPE 算法)
为什么 Tokenizer 知道该怎么切分?因为它是从海量文本中训练出来的。目前最主流的训练算法是 BPE(Byte Pair Encoding,字节对编码)。
3.1 BPE 算法核心思想
找规律,合并高频组合。
就像你读一本书,发现”人工”和”智能”总是成对出现,于是你把它们合并成一个词”人工智能”——BPE 算法做的就是这件事。
3.2 训练过程全演示
假设我们的训练语料只有一句话:人工智能改变人工生产
第 1 步:初始化 — 拆到最细
1 | 初始词表:[人, 工, 智, 能, 改, 变, 生, 产] |
第 2 步:统计相邻字符对频率
1 | (人, 工) → 出现 2 次 ← 最高频! |
第 3 步:合并最高频的对
1 | 合并规则 #1:人 + 工 → 人工 |
第 4 步:继续统计,继续合并
1 | (人工, 智) → 1 次 |
所有频率相同,选第一个合并:
1 | 合并规则 #2:人工 + 智 → 人工智 |
第 5 步:再合并
1 | 合并规则 #3:人工智 + 能 → 人工智能 |
训练产物(最终):
- 词表:
{人:0, 工:1, 智:2, 能:3, 改:4, 变:5, 生:6, 产:7, 人工:8, 人工智:9, 人工智能:10} - 合并规则:
人+工→人工,人工+智→人工智,人工智+能→人工智能
3.3 关键特性
| 特性 | 说明 |
|---|---|
| 渐进合并 | 从字符级别开始,逐步合并成更大的 Token |
| 频率驱动 | 出现越频繁的组合,越早被合并 |
| 词表可控 | 通过设定合并次数来控制词表大小(通常 3~10 万) |
| 递归参与 | 新合并的 Token 还能继续参与后续合并 |
补充知识:不同模型使用不同的分词算法
模型/公司 分词算法 OpenAI (GPT 系列) BPE Google (Gemini) Unigram / SentencePiece Meta (LLaMA) BPE (Byte-Level) Anthropic (Claude) BPE 变体 同一段文本,不同模型的 Tokenizer 切分结果可能不同,Token 数量也不同。
四、Tokenizer 的使用过程
训练完成后,Tokenizer 在实际使用中做两件事:编码和解码。
4.1 编码(文字 → 数字)
1 | 输入:"人工智能改变世界" |
4.2 解码(数字 → 文字)
1 | 模型输出:[10, 45, 78] |
补充知识:Token ID ≠ 语义
Token ID 只是编号,不具备语义信息。真正赋予语义的是模型内部的 Embedding 向量——每个 Token ID 对应一个高维向量,向量之间的距离才反映语义关系。
五、Token 与字数的换算关系
这是最实用的部分——Context Window 限制的是 Token 数量,不是字数。
5.1 换算公式
| 文本类型 | 换算比例 |
|---|---|
| 中文 | 1 Token ≈ 1.5 ~ 2 个汉字 |
| 英文单词 | 1 Token ≈ 0.75 个英文单词 |
| 英文字母 | 1 Token ≈ 4 个英文字母 |
| 代码 | 1 字符 ≈ 0.25 Token |
5.2 Context Window 真实容量
以 40 万 Token 窗口为例:
| 内容类型 | 可容纳量 |
|---|---|
| 中文文本 | 60 ~ 80 万汉字(约等于 2~3 本长篇小说) |
| 英文文本 | 30 万单词(约等于 3~4 本英文小说) |
| 代码 | 视语言和符号密度而定,通常比自然语言更费 |
5.3 什么内容更”费” Token?
| 省 Token | 费 Token |
|---|---|
| 常见词汇 | 生僻词 / 专业术语 |
| 规律性文本 | 乱码 / 混杂符号 |
| 高频短语 | 长路径 / Hash 值 |
| 自然语言 | 代码 / 日志 / JSON |
实测工具推荐:
- OpenAI Tokenizer — 在线可视化分词
- Python
tiktoken库 — 编程计算 Token 数
2
3
4
enc = tiktoken.encoding_for_model("gpt-4o")
tokens = enc.encode("人工智能改变世界")
print(f"Token 数: {len(tokens)}") # 输出实际 Token 数量
六、Token 的三大影响
6.1 成本控制
大模型 API 按 Token 计费,且输出 Token 比输入贵:
| 模型 | 输入价格 (每百万 Token) | 输出价格 (每百万 Token) | 输出/输入倍数 |
|---|---|---|---|
| GPT-4o | $2.50 | $10.00 | 4× |
| Claude 3.5 Sonnet | $3.00 | $15.00 | 5× |
| Gemini 1.5 Pro | $1.25 | $5.00 | 4× |
| DeepSeek V3 | ¥1.00 | ¥4.00 | 4× |
Agent 场景注意: Agent 任务通常需要多轮调用(规划 → 工具调用 → 观察 → 再规划),Token 消耗是简单问答的 10~50 倍,成本控制至关重要。
6.2 Context Window 边界
超出 Context Window 的内容会被截断或丢失,导致模型”看不见”关键信息。
1 | Context Window = 128K Token |
6.3 推理速度
生成的 Token 数量直接影响响应时间:
- 每个 Token 都需要一次前向传播
- 生成 100 Token 和 1000 Token 的时间差距约 10 倍
- 这就是为什么”简洁回答”比”长篇大论”响应更快
补充知识:Lost in the Middle 效应
研究发现,当 Context 很长时,模型对开头和结尾的内容记忆最好,对中间部分容易”遗忘”。
实践建议:
- 关键信息放在 Prompt 的开头或结尾
- System Prompt 不宜过长,避免挤占对话空间
- 长文档使用 RAG 而不是全部塞入 Context
七、Prompt 优化本质上是 Token 优化
理解了 Token,你就理解了 Prompt 优化的底层逻辑:用最少的 Token 传递最多的有效信息。
7.1 优化策略
| 策略 | 说明 | 效果 |
|---|---|---|
| 精简表达 | 去除冗余词汇和重复说明 | 节省输入 Token |
| 结构化格式 | 用表格/列表代替大段描述 | 信息密度更高 |
| 分步执行 | 复杂任务拆成多轮对话 | 避免单轮 Context 溢出 |
| 限制输出 | 明确要求”简洁回答”或限定字数 | 节省输出 Token(更贵!) |
| 善用 RAG | 只检索相关片段而非全文 | 大幅减少输入 Token |
7.2 反面教材
1 | ❌ 糟糕的 Prompt(浪费 Token): |
八、不同模型的 Tokenizer 差异
同一段文本,不同模型的 Token 数量可能相差很大:
1 | 文本:"人工智能正在改变世界" |
选型建议: 如果主要处理中文内容,优先选择对中文分词优化的模型(如 Qwen、GLM),可以显著降低 Token 消耗和成本。
九、总结:关于 Token 的五个关键认知
| # | 认知 | 一句话 |
|---|---|---|
| 1 | Token ≠ 字 | 它是亚词单元,由 Tokenizer 切分 |
| 2 | Token 是计费单位 | 输入+输出分别计费,输出更贵 |
| 3 | Token 决定 Context 边界 | 超限的内容模型看不见 |
| 4 | Token 影响速度 | 生成越多 Token,响应越慢 |
| 5 | Prompt 优化 = Token 优化 | 用最少 Token 传递最多有效信息 |
理解了 Token,你就掌握了大模型的”度量衡”——无论是评估成本、优化 Prompt、还是选择模型,Token 都是那把最基础的标尺。
参考资料