Harness Engineering 完全指南:从提示词工程到驾驭工程的范式跃迁
视频来源:《Harness Engineering 是什么?和提示词工程和上下文工程有什么关系?》 — UP主:小白debug(硅基文明简史系列)
核心一句话:AI 开发的本质,不是调用模型,而是围绕模型构建一个可约束、可记忆、可执行、可反馈、可编排的”驾驭外壳”。
本文以”小白debug”视频为主线重新组织,纠正了个别表述,并补充了视频中未深入讨论但同样重要的工程细节、业界实战和开源项目。
一、一个直击灵魂的问题
为什么同样用的是 Claude 3.5 / GPT-4,换一个 AI IDE,效果差距能这么大?
有了 AI,程序员是不是就不写代码了?那改写什么?
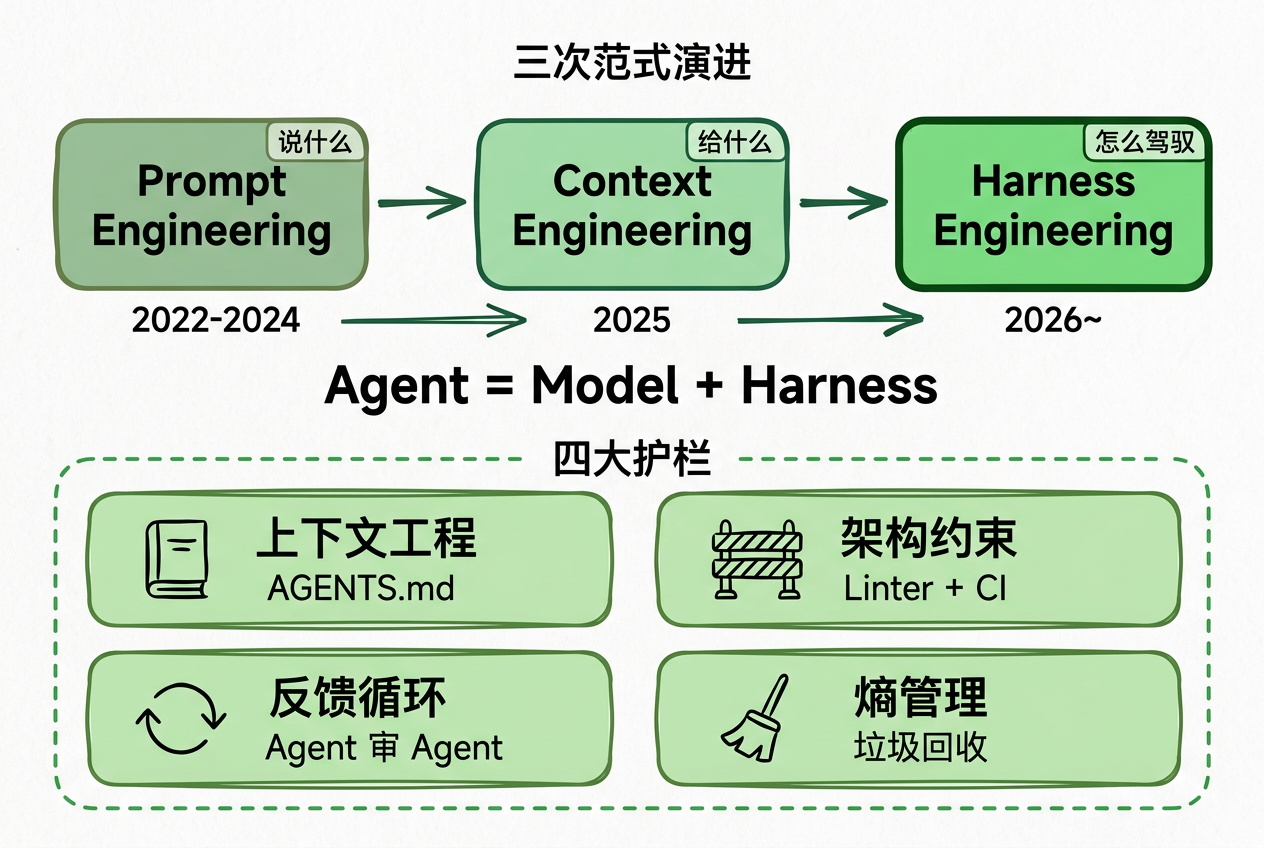
要回答这两个问题,必须把 Prompt Engineering、Context Engineering、Harness Engineering 三个概念串起来看。它们不是互相替代,而是层层嵌套、逐级包裹。
包含关系:Prompt Engineering ⊂ Context Engineering ⊂ Harness Engineering
二、回到原点:大模型本质上在做什么?
剥开 ChatGPT、Claude、Cursor、Claude Code 这些产品外壳:
- 本体:一个存放在磁盘上的超大参数文件
- 上电:加载进显卡显存 + 套一层 HTTP 接口 → 成为大模型 API
- 套壳:
- 加聊天界面 → ChatGPT 这类聊天 AI
- 加代码编辑器 → Cursor 这类 AI IDE
- 加执行环境 → Claude Code 这类 AI Agent
而大模型本身在做的事情非常简单:
基于当前输入的上下文,预测下一个最可能出现的 token。
由此直接推出四条结论:
- 输入越模糊 → 输出越泛泛
- 约束越明确 → 输出越稳定
- 信息越相关 → 回答越准确
- 信息越杂乱 → 模型越容易跑偏
AI 开发的本质,就是持续为模型”提供合适信息、控制信息结构、约束输出行为”的过程。
三、Prompt Engineering:让模型听懂人话
定义
有意识地调整和设计提示词,让模型稳定地朝你预期的内容和格式输出的技术手段。
一个日常例子
你丢一段代码给模型说:”加个排序”。
- ❌ 模型可能只回排序那一小段,上下文丢失
- ✅ 补一句:”给我完整函数代码,不要乱改我的代码” → 结果才合预期
提示词的典型构成
| 要素 | 作用 |
|---|---|
| 角色设定 | 你是一名资深 Java 工程师 |
| 任务目标 | 把这段代码重构成责任链模式 |
| 业务背景 | 当前在电商订单系统中 |
| 历史对话 | 之前讨论过的约束 |
| 参考文档 | API 文档、编码规范 |
| 限制 / 禁止事项 | 不允许引入新依赖 |
| 输出格式 | 返回 JSON / Markdown / 代码块 |
| 示例 / 评分标准 | few-shot 或 rubric |
它解决的问题
模型在缺乏明确引导时,会泛化回答、自由发挥、偏离预期。
它的局限
Prompt 再工程化,也只是”单次输入“的优化,无法解决:
- 上下文过长的问题
- 多轮对话信息丢失
- 模型不能读写文件、不能执行代码
四、Context Engineering:让模型看到该看到的东西
从 Prompt 到 Context
提示词越长越仔细,模型回答越准。反过来,回答不准就是模型知道得不够多。于是:
一次模型调用时模型能看到的全部信息 = 上下文(Context)
Prompt 只是 Context 的一部分。
上下文完整清单:
- 系统提示词(System Prompt)
- 用户提示词(User Prompt)
- 历史对话
- 外部文档 / RAG 检索结果
- 当前代码文件
- 工具调用结果(Tool Call Result)
- 错误日志 / 测试输出
- 环境信息(OS、时间、用户身份等)
定义
在有限的上下文窗口内,动态决定:给什么信息、什么时候给、不给哪些、顺序如何、以什么形式进入模型。
它解决的核心问题:上下文腐化(Context Corruption)
多轮对话会迅速打满上下文窗口。如果简单压缩或丢弃信息,会出现:
- 模型”记不住”之前说过的限制
- 前后回答自相矛盾
- 忘记输出格式要求
- 越做越偏离原始任务
这就是”上下文腐化”——目标漂移 + 记忆偏移 + 回答失真。
三个核心动作:召回 → 压缩 → 组装
| 动作 | 做什么 | 涉及技术 |
|---|---|---|
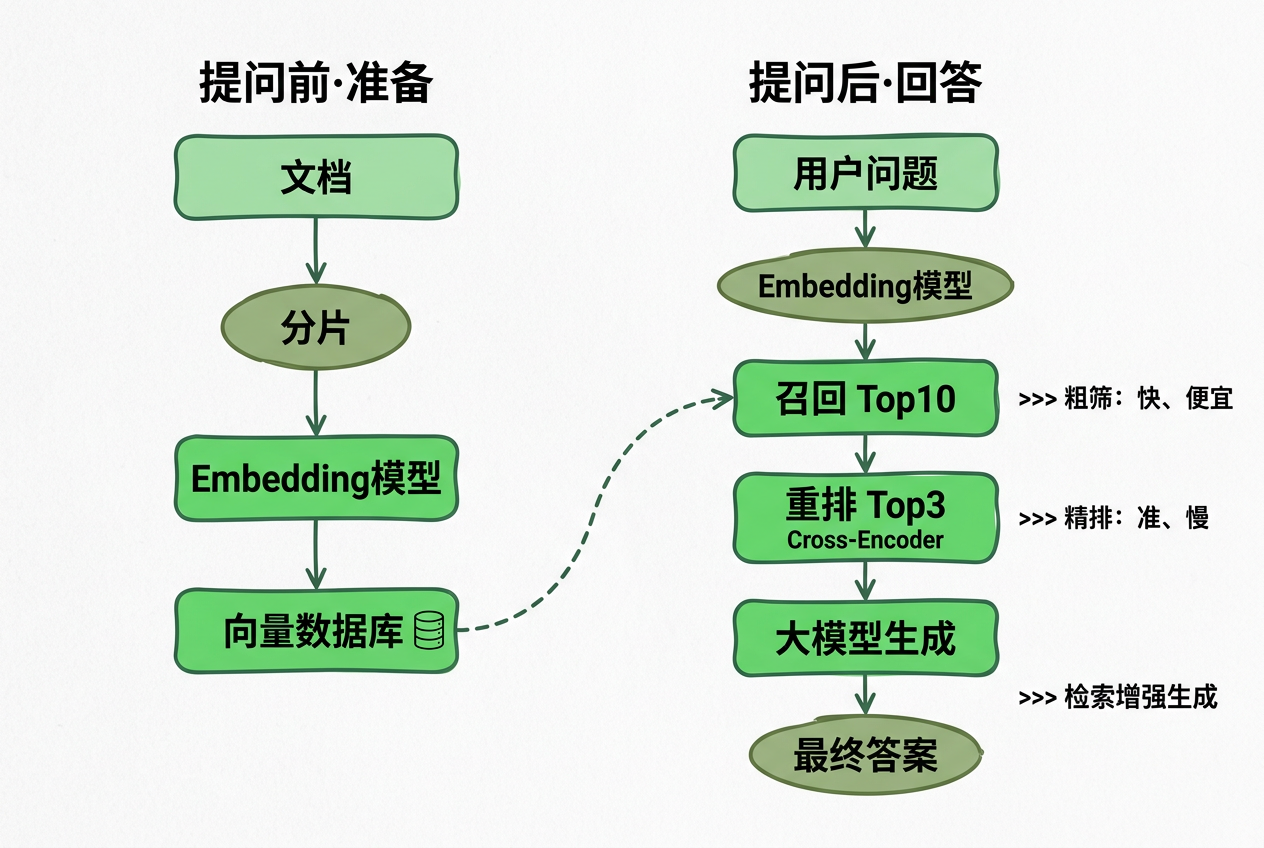
| 召回(Retrieve) | 从外部新闻、历史聊天、代码环境、运行报错中,找到当前任务最相关的信息 | RAG、向量检索、Memory |
| 压缩(Compress) | 把信息变小:摘要、提炼、去重、结构化提取、分块总结 | LLM 总结、结构化提取 |
| 组装(Assemble) | 把信息按优先级排好:系统规则 → 当前任务 → 限制 → 背景 → 代码 → 反馈 → 待执行动作 | 越靠后的内容越容易被模型关注 |
关键洞察:不同 AI 工具的上下文工程策略不同,所以即使用同一个模型,Cursor、Claude Code、Trae 的效果也会有明显差异。
补充:40% 上下文阈值(视频未提及)
Dex Horthy 的实验发现,168K token 的上下文窗口,用到约 40% 时,模型质量就开始明显下降:
| 区间 | 表现 |
|---|---|
| 0–40%(Smart Zone) | 推理聚焦、工具调用准确 |
| > 40%(Dumb Zone) | 幻觉增多、兜圈子、格式混乱 |
最佳实践:监控上下文利用率,超过 40% 就主动触发压缩或任务交接(Context Reset),不要硬撑到窗口爆炸。
五、Agent 是怎么冒出来的:一个 for 循环
Prompt Engineering 和 Context Engineering 让模型”更聪明”,但它只能聊天,没法干活。
怎么让它干活?给它加”手脚”:
- bash 沙箱
- 文件系统读写
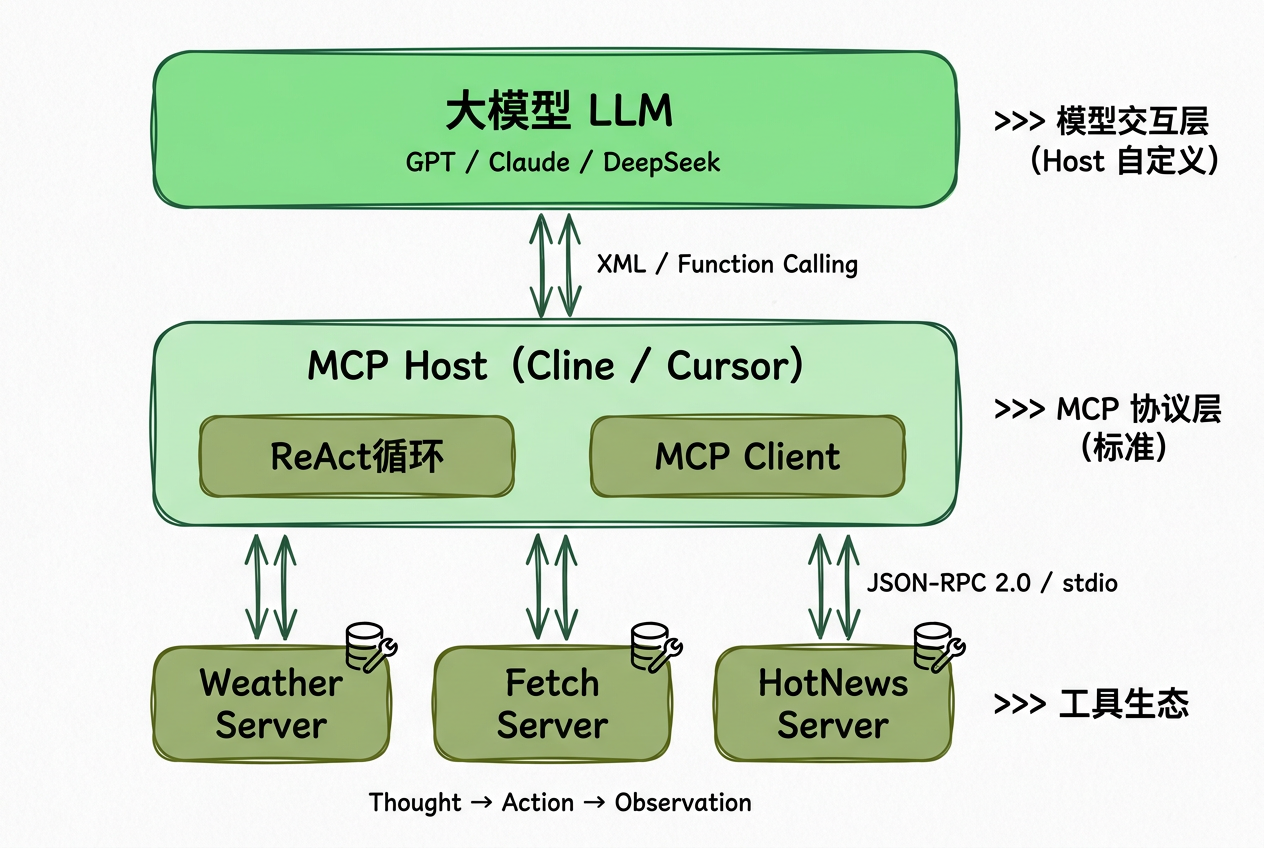
- MCP(Model Context Protocol)工具
- 浏览器、数据库、API 调用
→ 它就能像人一样操作工具、读写代码、执行命令。这层叫执行层。
把”上下文组装 → 发给模型 → 模型思考 → 外部程序执行 → 结果回传上下文”串成一个循环,就是 ReAct(Reasoning + Acting):
1 | ┌──────────────────────────────────────────────┐ |
Agent 的本质 = 一个 for 循环。
大模型负责思考,外部程序负责执行,循环直到任务完成。
但是……仅有 ReAct 循环是不够的。它会出问题:
| 问题 | 表现 |
|---|---|
| 一直试错但不收敛 | 循环开了又开,就是做不出来 |
| 能执行但容易跑偏 | 往错误方向狂奔,浪费一堆 token |
| 调了工具但不知道什么时候停 | 无法判定”任务做完了” |
| 改代码很快,但越改越乱 | 无架构约束,技术债爆炸 |
| 上下文腐化 | 循环越长 → 目标和约束被冲淡 → 模型忘了最初要做什么 |
→ 需要给这个 for 循环加”护栏”、”仪表盘”和”交通规则”。这就是 Harness Engineering。
六、Harness Engineering:给大模型造一辆车
定义
Harness Engineering = 围绕大模型构建一层工程化”驾驭外壳”,把模型接入规则、上下文、工具、反馈、记忆和编排机制,最终让模型从”会回答”变成”能稳定完成任务并交付结果“。
Harness 本意是”束具、牵引装置”——就像马的缰绳、马鞍、马蹄铁。
核心公式
Agent = 大模型 + Harness
不属于大模型的那部分,都属于 Harness Engineering 的范畴。
关键洞察
大模型越强,外壳可以做得越薄,但无论怎样,这层外壳都不会消失。
七、Harness 的四大层级(视频主线)
小白debug 视频中给出的是四层架构,对应 Agent for 循环中要解决的四个关键问题:
Layer 1 — 执行层(Execution Layer)
解决:”模型只会说,不会做”的问题。
提供能力:
- bash 沙箱(如 E2B、Daytona、Microsandbox)
- 文件系统读写
- MCP 工具集(官方/自定义)
- 浏览器自动化(Playwright、Puppeteer MCP)
- 数据库 / API 调用
作用:把模型推理结果转化为对外部世界的实际动作。
Layer 2 — 记忆层(Memory Layer)
解决:循环越长 → 上下文越膨胀 → 目标和约束被冲淡的问题。
做法:每次给模型的上下文都稳定注入可复用的核心信息:
- 项目目标、需求背景
- 技术栈
- 代码风格、命名规范
- 禁止事项、安全红线
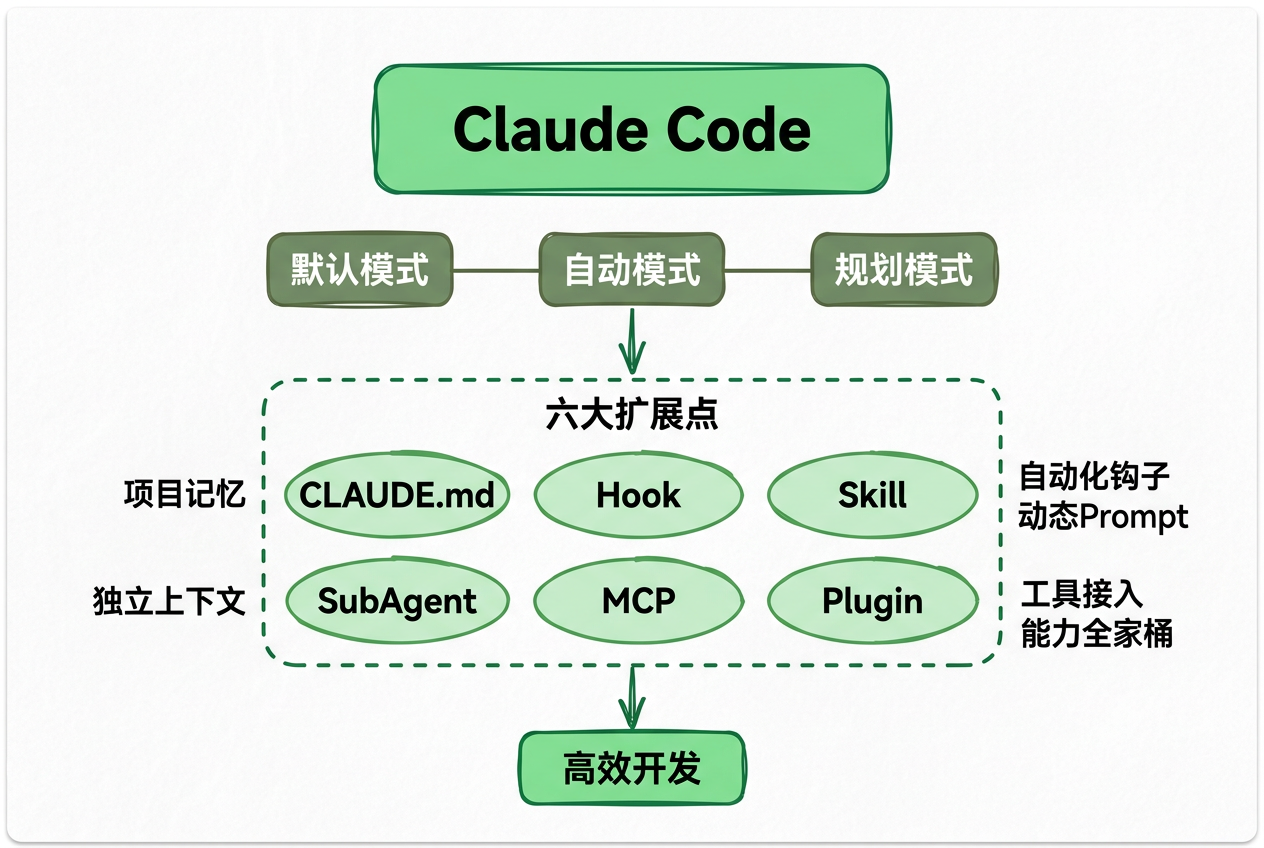
规则文件的命名(各家不一):
| AI 工具 | 规则文件 |
|---|---|
| Claude Code | CLAUDE.md |
| Cursor | .cursor/rules/*.mdc |
| Trae | 自家 rules 文件 |
| HashiCorp 等倡议 | AGENTS.md |
长度膨胀了怎么办?→ 拆分 + 路由:
1 | AGENTS.md (~100 行,只作为目录) |
只注入文件路径索引,模型需要时再主动 read 加载。
精髓:每一行规则文件,对应一个历史上真实发生过的失败案例,形成持续积累的”免疫系统”。
Layer 3 — 反馈层(Feedback Layer)
解决:让 Agent 具备”自知之明”,能自我发现并修复问题。
机制:
- Agent 每次写完代码后,自动跑 linter、单元测试、集成测试
- 失败时把错误信息、测试输出、堆栈回传到上下文
- 驱动下一轮循环去自动修复
→ 形成 “执行 → 观察 → 修复 → 再执行“ 的闭环。
进阶实践:
- Linter 错误消息 = 修复指令:不仅告诉模型哪里错,还告诉它怎么改
- 如果测试通过但代码有 Bug → Harness 判定测试无效,强迫重写测试
- GAN 式三智能体架构:Planner → Generator ⇄ Evaluator
1 | ❌ Error: Module 'runtime' cannot import from 'ui' |
Layer 4 — 编排层(Orchestration Layer)
解决:循环缺乏全局规划和清晰结束目标 → 跑偏或陷入死循环。
做法:将大任务拆解为多个有明确执行标准的子任务:
1 | 1. 确认开发规范 |
作用:以全局规划为核心,对任务做拆解与全流程管控。
四层合起来 = Harness Engineering
编排层 + 执行层 + 反馈层 + 记忆层 = 包裹大模型的工程外壳。
八、从四层到六层:业界的进一步细化
视频中给出的是清晰的四层心智模型。业界(Anthropic、OpenAI 工程实践)在此基础上进一步细化为六层架构,适合系统性地设计大型 Agent 平台:
| 层级 | 名称 | 解决什么问题 | 对应视频四层 |
|---|---|---|---|
| L1 | 信息边界层 | Agent 该知道什么、不该知道什么 | 记忆层的上游 |
| L2 | 工具系统层 | 怎么跟外部世界交互 | 执行层 |
| L3 | 执行编排层 | 多步骤任务怎么串起来 | 编排层 |
| L4 | 记忆与状态层 | 长任务中间结果怎么管 | 记忆层 |
| L5 | 评估与观测层 | Agent 怎么知道自己做对了 | 反馈层 的验证侧 |
| L6 | 约束、校验与恢复层 | 出错了怎么办 | 反馈层 的恢复侧 |
核心矛盾:确定性 vs 不确定性
传统软件是确定性的,AI 系统是概率性的。Harness 的解法是:
不承诺消除不确定性,而是通过全程可追溯性建立信任。
只有可以被看见的,才可以被信任。
九、起源与术语澄清
⚠️ 视频里说”2026 年 OpenAI 在一篇博客文章中提到了 Harness Engineering”——严格来说,这个时间线并不完整:
| 时间 | 事件 |
|---|---|
| 2026-02-05 | HashiCorp 联合创始人 Mitchell Hashimoto 在个人博客中首次提出该术语 |
| 6 天后 | OpenAI 发布《Harness Engineering: leveraging Codex in an agent-first world》详细实验报告 |
| 随后 | Martin Fowler 撰文分析、Anthropic 发布工程实践指南,迅速成为开发者社区热词 |
“Harness Engineering is the idea that anytime you find an agent makes a mistake, you take the time to engineer a solution such that the agent will not make that mistake again in the future.”
—— Mitchell Hashimoto
四个核心动词:
| 动作 | 含义 | 类比 |
|---|---|---|
| Constrain(约束) | 设定边界,防止 Agent 越界 | 高速公路的护栏 |
| Inform(告知) | 提供上下文,让 Agent 理解任务 | 导航仪的地图 |
| Verify(验证) | 自动检查输出质量 | 质检员的检查表 |
| Correct(纠正) | 基于验证结果自动迭代 | 自动驾驶的路径修正 |
十、三者关系一图流(本文最重要的一张表)
| 工程层级 | 优化对象 | 解决的核心问题 | 一句话 |
|---|---|---|---|
| Prompt Engineering | 单次输入措辞 | 模型无引导、乱说话 | 怎么把要求说清楚 |
| Context Engineering | 信息输入与组织 | 上下文腐化、知识边界 | 给模型看什么、怎么给 |
| Agent (ReAct) | 循环执行机制 | 模型只会说不会做 | 怎么让模型调工具持续行动 |
| Harness Engineering | 运行环境全栈 | Agent 跑偏、无法交付 | 怎么把以上能力整合成可控、可交付的完整工程系统 |
生动类比:
- Prompt Engineering = 对马喊话的技巧
- Context Engineering = 给马看的地图
- Harness Engineering = 给马造一条高速公路,配上护栏、限速牌、加油站和交通管制
包含关系:Prompt ⊂ Context ⊂ Harness
(Agent 是 Harness 中的执行形态核心,但 Harness 的范围远大于 Agent。)
十一、常见误区(小白debug & 业界共识)
| ❌ 误区 | ✅ 正确认知 |
|---|---|
| Prompt 越长越好 | 越清晰、越相关、越结构化越好 |
| 上下文越多越好 | 越相关越好,超过 40% 要主动压缩 |
| 有了 Agent 就不用管过程 | Agent 越强,越需要明确边界、终止条件和验证机制 |
| 模型强了外壳就不重要 | 外壳可以变薄,但永不消失 |
| Harness = 一个新框架 | Harness 是工程思维方式,不是单一工具或库 |
十二、落地:从零搭建一个 Harness
方案一:Claude Code 原生支持(最轻量)
Claude Code 已原生支持四层能力。最小可行动作就是:在仓库根目录写一个 CLAUDE.md:
1 | # 项目:订单中台 |
精髓:每一行规则对应一个历史失败案例。
方案二:SDD(Spec-Driven Development,规范驱动开发)
配合 spec-kit 等插件,走完整的规范驱动流程:
1 | 1. 生成约束文件,明确需求(What + Why) |
视频作者评价:”spec-kit 整体还是不够强,相信很快会有更加全面的替代方案出现。”
实施路线图(P0 → P2)
| 阶段 | 行动 | 说明 |
|---|---|---|
| P0 | 创建 AGENTS.md / CLAUDE.md |
~100 行目录,详细规则拆到子文档 |
| P0 | 构建自定义 Linter | 错误消息里直接告诉 Agent 怎么改 |
| P0 | 团队知识进仓库 | Git 仓库是唯一事实源,Slack/Wiki 对 Agent = 不存在 |
| P1 | 分层管理上下文 | 渐进式披露,避免窗口爆炸 |
| P1 | 建立进度文件 | JSON 格式追踪状态,防止 Agent 乱改 |
| P1 | 给 Agent 端到端验证能力 | 接入 Playwright,让它像用户一样自测 |
| P1 | 控制上下文利用率 | 目标 ≤ 40%,超过触发 Context Reset |
| P2 | Agent 专业化分工 | 去重、优化、文档等专职角色 |
| P2 | 定期垃圾回收 | 后台 Agent 扫描并清理冗余代码 |
| P2 | 可观测性集成 | 接入 Langfuse / AgentOps |
| P2 | Trace 驱动迭代 | 基于数据而非感觉改进 Harness |
十三、一线团队实战案例(视频没讲但极具启发)
案例一:OpenAI Codex —— 3 人 5 个月 100 万行代码
| 指标 | 数据 |
|---|---|
| 团队规模 | 3–7 人 |
| 开发周期 | 5 个月 |
| 代码产出 | ~100 万行 |
| 手写代码 | 0 行 |
| 人均日 PR | 3.5 个 |
五大方法论:
- 地图式文档 (
AGENTS.md):只写 ~100 行目录,渐进式披露 - 机械化约束:自定义 Linter,报错信息自带修复方法
- 可观测性接入:Chrome DevTools Protocol,Agent 能自己截图测性能
- 熵管理:后台自动扫描并清理低质量代码
- 仓库即事实源:知识必须在 Git 仓库里
案例二:Anthropic —— GAN 式三智能体架构
Nicholas Carlini 的 C 编译器项目:
- 16 个并行 Claude Opus 实例
- 两周时间,10 万行 Rust 代码
- GCC 测试通过率 99%
三智能体架构:
1 | Planner (大胆规划) |
关键经验:
- 日志写文件不打控制台(防上下文污染)
- 测试子采样:每个 Agent 跑 1–10%,集体覆盖全量
- Agent 角色专业化(去重、优化、文档等专职 Agent)
案例三:Stripe Minions —— 每周 1300+ 无人值守 PR
Blueprint 模式(混合状态机):
1 | 触发 → 预热 Devbox → Blueprint 编排 → |
核心思想:模型不运行系统,系统运行模型。确定性门禁”夹住”概率性的 LLM。
核心组件:
| 组件 | 功能 |
|---|---|
| Devbox | 预装环境的 EC2 实例,启动仅需 10 秒 |
| Toolshed MCP | 集中管理近 500 个工具 |
| 反馈回路 | Pre-push hook 秒级修 lint,推送后最多跑 2 轮 CI(300 万+测试) |
案例四:LangChain —— 排名从 30 跃升至 5
只优化 Harness,底层模型参数完全未改动:
- Terminal Bench 2.0 得分从 52.8% 飙升至 66.5%
- 全球排名从 30 → 5
启示:一个格式的改变,等于十个模型升级。
案例五:Can Boluk —— 编辑格式改变一切
把 Agent 的代码编辑格式从传统 patch 改为 Hashline 格式:
1 | 42:a3f| let x = compute(); |
结果:Grok Code Fast 1 的基准得分从 6.7% → 68.3%。
结论:决定 Agent 效果的最大变量,往往不是模型本身,而是其所处的环境。
案例六:Mitchell Hashimoto —— 单 Agent 六步进阶
Harness Engineering 术语创造者的个人实践:
| 步骤 | 实践 |
|---|---|
| 1 | 放弃聊天模式,直接在干活环境使用 |
| 2 | 复现自己的工作(每件事做两次,手动+Agent) |
| 3 | 下班前启动 Agent 跑长任务 |
| 4 | 外包确定性任务,关掉通知 |
| 5 | 工程化 Harness——每犯一次错,就加规则永不再犯 |
| 6 | 始终有 Agent 在运行 |
十四、工具生态(落地清单)
安全执行沙箱
| 工具 | 特点 | 启动时间 |
|---|---|---|
| E2B | 开源,支持多语言,轻量级 | < 200ms |
| Daytona | 企业级,支持状态持久化 | < 90ms |
| AgentSandbox | 专注 Python/Bash,API 友好 | 可变 |
| Microsandbox | 开源,VM 级隔离 | < 1s |
浏览器自动化
| 工具 | 特点 |
|---|---|
| BrowserUse | 开源,78,000+ GitHub stars |
| Nanobrowser | Chrome 扩展,多 Agent 工作流 |
| Playwright | 微软开源,Anthropic 推荐的 E2E 方案 |
| Puppeteer MCP | 通过 MCP 协议接入浏览器自动化 |
可观测性
| 工具 | 功能 |
|---|---|
| Langfuse | 开源,追踪 Agent 推理链 |
| AgentOps | 专注 Agent 性能监控 |
| Helicone | LLM 调用追踪与成本分析 |
| Galileo | 企业级 Agent 可观测性 |
编排框架
| 框架 | 特点 | 适用场景 |
|---|---|---|
| LangChain / LangGraph | 生态完善,支持复杂状态流 | 企业级复杂应用 |
| CrewAI | 角色扮演,多 Agent 协作 | 团队协作场景 |
| AutoGen | 微软出品,对话驱动 | 研究 / 实验 |
| OpenAI Agents SDK | OpenAI 原生,深度集成 | OpenAI 生态应用 |
Harness 与传统框架的分层关系
1 | ┌──────────────────────────────────┐ |
注意:Harness 不是 Agent 框架的替代品,而是更上层的控制系统。模型正在吸收框架 80% 的功能,但持久化、可观测性、错误恢复等剩余 20% 正是驾驭层的核心价值。
十五、GitHub 高星开源实践项目
1. DeerFlow 2.0(字节跳动) — ⭐ 60.4K
GitHub:bytedance/deer-flow
字节跳动将第一代 Deep Research 框架从零重写,升级为 Super Agent Harness。
Harness 实践亮点:
| 实践维度 | 具体做法 |
|---|---|
| 子 Agent 编排 | Lead Agent 动态生成子 Agent,各自独立上下文和工具,并行执行后汇总 |
| 技能系统 | Markdown 定义的结构化技能模块,渐进式加载 |
| 沙箱隔离 | Docker 容器级安全隔离,默认禁用主机 Bash |
| 上下文工程 | 自动摘要已完成子任务,压缩不相关内容 |
| 长期记忆 | 跨会话持久化存储用户偏好、写作风格 |
| 可观测性 | 原生集成 LangSmith / Langfuse |
2. Claw Code — ⭐ 48K+
GitHub:instructkr/claw-code
Claude Code 架构的净室重写(Clean-Room Rewrite),用 Python + Rust 混合架构重新实现了 Anthropic 闭源的 51 万行 TypeScript 代码。
| 实践维度 | 具体做法 |
|---|---|
| 工具系统 | 19 个内置工具,每个独立权限 + 沙箱 |
| 查询引擎 | 管理所有 LLM 调用、响应流、缓存策略 |
| 多 Agent Swarm | 子 Agent 并行执行,隔离上下文 + 共享内存 |
| MCP 集成 | 6 种传输类型(Stdio, SSE, HTTP, WebSocket, SDK, Proxy) |
| 三级权限 | 策略引擎 / 拒绝列表 / 交互式审批 |
| Rust 性能核心 | 72.9% Rust,零依赖 JSON 解析器 |
3. OpenHarness(港大 HKUDS) — ⭐ 8.7K
GitHub:HKUDS/OpenHarness
最正统的 Harness Engineering 开源实现 —— 用 1.1 万行 Python 复刻了 Claude Code 51 万行代码的核心能力。学习 Harness 架构的最佳项目。
10 大子系统:Engine / Tools / Skills / Plugins / Permissions / Hooks / Commands / MCP / Memory / Coordinator。
4. awesome-agent-harness(资源索引) — ⭐ 180
GitHub:Picrew/awesome-agent-harness
收录 145 个 Harness Engineering 相关项目和工具。
项目对比速查
| 项目 | Stars | 代码量 | 适合场景 |
|---|---|---|---|
| DeerFlow 2.0 | 60.4K | 大型项目 | 生产级长周期多 Agent 编排 |
| Claw Code | 48K+ | 51 万行重写 | 研究 Claude Code 架构,Rust 高性能 Harness |
| OpenHarness | 8.7K | 1.1 万行 | 最佳学习项目 — 代码精简、架构清晰 |
| awesome-agent-harness | 180 | 索引 | 资源导航、工具选型 |
十六、写给程序员的温情金句
视频结尾那段话,值得反复咀嚼:
“有了 Harness Engineering 之后,程序员的工作内容就从写代码,慢慢改为写规则和 skill。
所以有句话是这么说的:你那些拿了 N+1 的同事其实从未离开你,
他只是变成了 skill,默默陪伴你。
你就说暖不暖心吧。”—— 小白debug
被裁掉(拿 N+1 赔偿)的同事,那些”他才知道的坑”、”他积累的最佳实践”、”他踩过的雷”——以 skill 文件、rules 文件、AGENTS.md 的形式被固化保存在项目中,在 Agent 每一次执行时继续发挥作用。
这不是段子,这就是 Harness Engineering 的终极含义:
组织的经验 → 代码化 → Agent 可调用 → 持续复利。
十七、总结
Harness Engineering 代表了 AI 工程领域的第三次范式跃迁。它不是一个框架、不是一个工具,而是一种工程思维的转变:
为了获得更高的 AI 自主性,运行时必须受到更严格的约束。
三层工程逐级包裹,缺一不可:
1 | ┌────────────────────────────────────────┐ |
就像高速公路——正是因为有了护栏、限速牌和车道线,车才能安全地开到 120 码。
模型决定上限,工程决定落地效果。
大模型越强,外壳可以做得越薄,但这层外壳永远不会消失。
Harness Engineering 最终将不再是一个专门的术语,而是成为像”版本控制”一样标准化的工程基础设施。能够掌握这一范式的团队,将在生产力上获得数量级的优势。
参考资源
视频 & 主线讲解
- 小白debug — Harness Engineering 是什么?和提示词工程和上下文工程有什么关系?(本文视频来源)
- code秘密花园 — 最近爆火的 Harness Engineering 到底是啥?一期讲透!
原始出处
- Mitchell Hashimoto — Harness Engineering(原始博客)
- OpenAI — Harness Engineering: leveraging Codex in an agent-first world
- Anthropic — Building effective agents
- Martin Fowler — AI Coding Agents
中文深度解析
- 掘金 — Harness Engineering 是什么:从提示词工程、上下文工程到驾驭工程
- JavaGuide — 一文搞懂 Harness Engineering
- 菜鸟教程 — Harness Engineering
开源项目