从 LLM 到 Agent Skill:一文打通 AI 底层逻辑
从 LLM 到 Agent Skill:一文打通 AI 底层逻辑
本文整理自 B 站 UP 主 马克的技术工作坊 的视频 《从 LLM 到 Agent Skill,一期视频带你打通底层逻辑!》,并补充了额外的知识点和个人理解。
AI 领域每天都在冒新名词:LLM、Token、Prompt、Agent、Agent Skill……这些词你可能都听过,但你真的能准确说出每个概念的确切含义吗?
本文不讲商业概念,而是从底层工程视角,将这些概念逐一拆解,帮你建立完整的认知框架。
一、LLM(Large Language Model,大语言模型)
是什么
大语言模型,简称大模型。目前绝大多数大模型基于 Google 团队 2017 年提出的 Transformer 架构。
发展简史
| 时间 | 里程碑 |
|---|---|
| 2017 | Google 发表 “Attention is All You Need”,提出 Transformer |
| 2022.11 | OpenAI 发布 GPT-3.5 (ChatGPT),首个真正可用的大模型 |
| 2023.03 | GPT-4 发布,拉高能力天花板 |
| 2023-2026 | Claude、Gemini、DeepSeek 等百花齐放 |
核心原理:文字接龙
LLM 的本质就是一个”文字接龙“游戏:
1 | 用户输入: "马克的视频怎么样?" |
每次只预测一个 Token,然后把它追加到输入,再预测下一个——这就是大模型逐字生成内容的底层原理。
补充知识:Temperature 参数
模型预测下一个 Token 时会计算每个候选词的概率。temperature参数控制了预测的”随机性”:
temperature = 0:始终选概率最高的词,输出最确定temperature = 1:按原始概率分布采样,更有创造力temperature > 1:更随机,可能产生意外的有趣输出
二、Token(令牌)
是什么
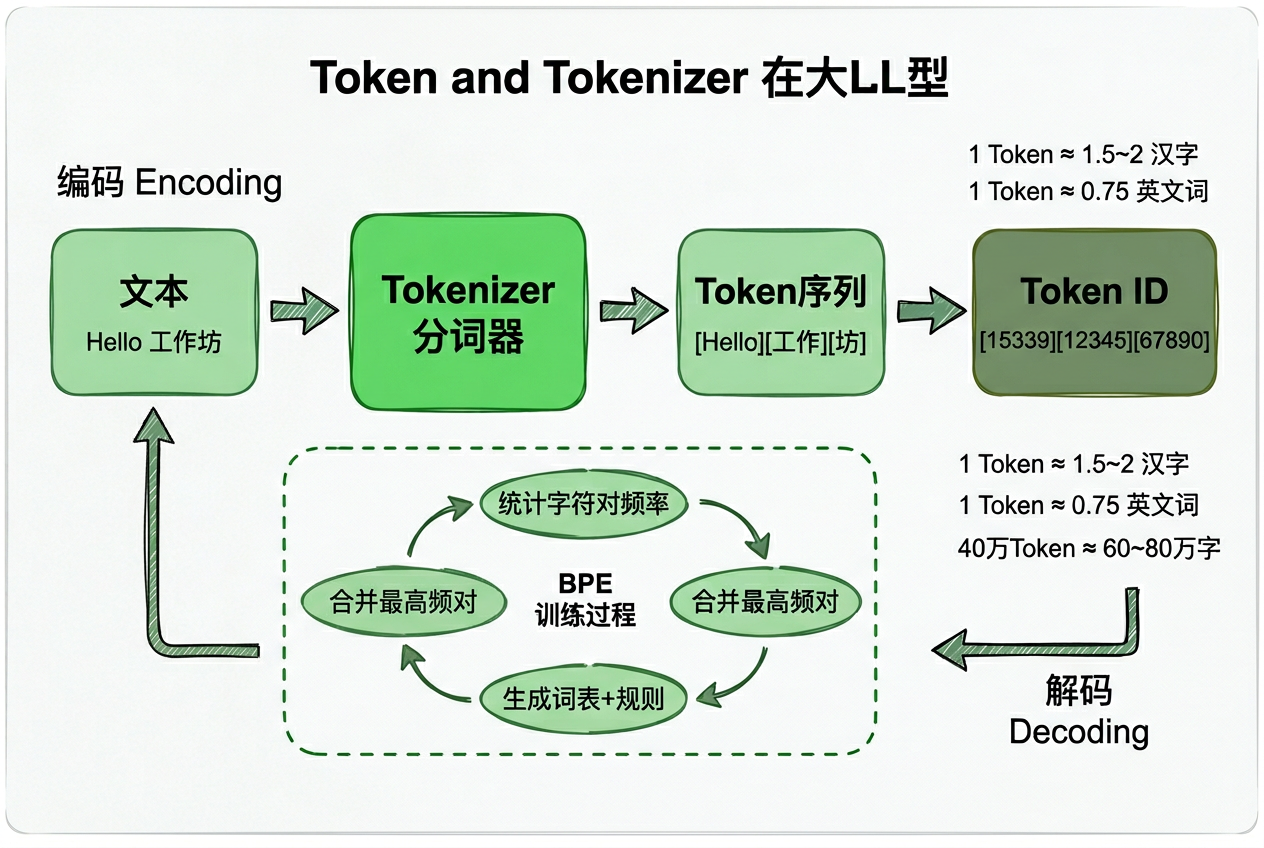
Token 是大模型处理文本的最基本单元。大模型只认识数字,不认识文字,因此需要一个中间人——Tokenizer(分词器)。
Tokenizer 的工作
1 | 编码过程(文字 → 数字): |
Token 与词的关系
Token 和”词”并不是一一对应的:
| 情况 | 示例 |
|---|---|
| 一个词 = 一个 Token | hello → [hello] |
| 一个词 = 多个 Token | 工作坊 → [工作] [坊] |
| 一个字符 = 多个 Token | ☑ → [â] [ś] [ij] |
换算比例
经验法则: 1 Token ≈ 0.75 个英文单词 ≈ 1.5 ~ 2 个汉字
这个比例在估算 API 成本和 Context Window 用量时非常有用。
三、Context(上下文)
是什么
Context 是大模型每次处理任务时接收到的信息总和,可以理解为大模型的”临时记忆体“。
它包含的内容远比你想象的多:
1 | Context = System Prompt (系统设定) |
Context Window(上下文窗口)
Context Window 代表 Context 能容纳的最大 Token 数量,就像一个有固定大小的”滑动窗口”。
| 模型 | Context Window |
|---|---|
| GPT-4 (初版) | 8K / 32K |
| Claude 3.5 Sonnet | 200K |
| Gemini 1.5 Pro | 1M |
| GPT-4o | 128K |
| Claude Opus 4 | 200K |
补充知识:RAG(Retrieval Augmented Generation)
当文档超出 Context Window 时怎么办?这就需要 RAG 技术:
- 将长文档切分成小块(Chunk)
- 将每个块转为向量存入向量数据库
- 用户提问时,先检索最相关的块
- 只把相关的块塞入 Context,而不是整个文档
这样既控制了成本,又保证了回答的相关性。
四、Prompt(提示词)
是什么
Prompt 是给大模型的具体问题或指令。好的 Prompt 能显著提升输出质量。
两种 Prompt
| 类型 | 设置者 | 作用 | 示例 |
|---|---|---|---|
| System Prompt | 开发者 | 定义模型人设和规则 | “你是一个耐心的数学老师,不要直接给答案” |
| User Prompt | 用户 | 具体的任务指令 | “3 加 5 等于几?” |
模型会结合两者来生成回答。System Prompt 像是”教师手册”,User Prompt 是”学生的提问”。
Prompt Engineering(提示词工程)
研究如何写出清晰、具体、明确的 Prompt,以获得更好输出的学科。核心原则:
- 明确角色:告诉模型它是谁
- 具体任务:说清楚要做什么
- 格式要求:指定输出格式
- 提供示例:给 Few-shot 例子
- 设置约束:限定回答范围
补充知识:常见 Prompt 技巧
- Chain of Thought (CoT):让模型”一步一步思考”
- Few-Shot:提供几个输入→输出示例
- Tree of Thoughts:让模型探索多条推理路径
- Self-Consistency:多次生成取投票结果
五、Tool(工具)
是什么
Tool 本质是一个函数,用于让大模型感知和影响外部环境。
大模型本身只会”文字接龙”,不知道今天天气、不能发邮件、不能查数据库——但通过 Tool,它可以做到这些。
调用流程
一次完整的 Tool 调用涉及四个角色:用户、平台、大模型、工具
1 | 用户 → 平台:今天北京天气怎么样? |
关键点: 大模型自己不执行工具,它只是告诉平台”我要调用什么”,由平台来实际执行。
补充知识:Function Calling
Tool 的技术实现叫 Function Calling。开发者需要:
- 用 JSON Schema 定义工具的名称、参数、描述
- 把工具列表放入 Context
- 模型会在需要时输出特定格式的调用指令
- 应用层解析指令并执行对应函数
六、MCP(Model Context Protocol,模型上下文协议)
是什么
MCP 是一套统一的工具接入标准,由 Anthropic 于 2024 年底发布。
解决什么问题
在 MCP 之前,每个 AI 平台(ChatGPT、Claude、Cursor……)的工具接入方式各不相同,开发者要为每个平台单独适配。
1 | MCP 之前: |
类比理解
MCP 就像手机的 Type-C 接口:
- Type-C 之前:每个厂商用不同的充电口
- Type-C 之后:一根线走天下
MCP 对 AI 工具的意义,就像 Type-C 对充电的意义——统一标准,降低接入成本。
补充知识:MCP 架构
MCP 采用 Client-Server 架构:
- MCP Server:工具提供方,暴露工具能力
- MCP Client:AI 平台方,集成在 IDE/Chat 中
- 传输层:支持 stdio、HTTP SSE 等多种方式
目前 Cursor、Claude Code、CodeBuddy 等主流 AI 开发工具都已支持 MCP。
七、Agent(智能体)
是什么
Agent 是能够自主规划、自主调用工具直至完成用户任务的系统。
与简单 Tool 调用的区别
简单 Tool 调用是”一问一答”,而 Agent 是连续思考、分步决策:
1 | 简单 Tool 调用: |
核心特征
- 自主规划:根据目标自行制定执行计划
- 工具调用:按需使用可用的 Tool
- 循环决策:观察结果 → 思考下一步 → 执行 → 再观察
- 目标导向:持续执行直到任务完成
补充知识:常见 Agent 架构模式
模式 特点 ReAct Reasoning + Acting,思考和行动交替进行 Plan and Execute 先制定完整计划,再逐步执行 Reflection 执行后自我反思,改进下一轮 Multi-Agent 多个 Agent 协作,各司其职
八、Agent Skill(智能体技能)
是什么
Agent Skill 是提前写好并塞给 Agent 的一份说明文档(通常是 Markdown 格式),用于规定做事的步骤、规则和格式。
可以理解为 Agent 的”工作手册“或”SOP(标准操作流程)“。
为什么需要 Skill
| 没有 Skill | 有 Skill |
|---|---|
| 每次都要写冗长的 Prompt | 一次编写,重复使用 |
| 输出格式不稳定 | 严格按规定格式输出 |
| 执行流程不可控 | 按预定步骤执行 |
| 难以分享给他人 | 可以分享和复用 |
Skill 文件结构
一个典型的 Agent Skill 包含两层:
1 | # 元数据层 |
实际使用效果
用户只需说”出门带什么“,Agent 就会:
- 自动加载这个 Skill
- 按文档定义的流程调用工具
- 按规定格式输出结果
九、完整知识体系串联
把所有概念串起来,就是 AI 从”文字接龙”进化到”自主智能体”的完整路径:

1 | LLM(大语言模型) |
演进本质
| 阶段 | 能力 | 类比 |
|---|---|---|
| LLM | 单轮文字生成 | 会说话的大脑 |
| + Context | 多轮记忆 | 有短期记忆的大脑 |
| + Tool | 感知和影响外部世界 | 有手有脚 |
| + MCP | 标准化接入任何工具 | 万能适配器 |
| + Agent | 自主规划和决策 | 有独立思考能力的员工 |
| + Skill | 可复用的经验文档 | 带着 SOP 上岗的熟练员工 |
十、写在最后
理解了从 LLM 到 Agent Skill 的完整演进路径,你就能看清当前所有 AI 产品的本质:
- ChatGPT / Claude:LLM + Context + Prompt
- Cursor / CodeBuddy:LLM + Context + Tool + MCP + Agent
- Claude Code / Devin:LLM + Context + Tool + MCP + Agent + Skill
未来不管 AI 产品怎么变,核心思想不变:模型生成、工具执行、协议连接、Agent 组织、Skill 沉淀。
掌握了底层逻辑,你就不会被层出不穷的新名词搞迷糊,而是一眼看穿它们的本质。
参考资料